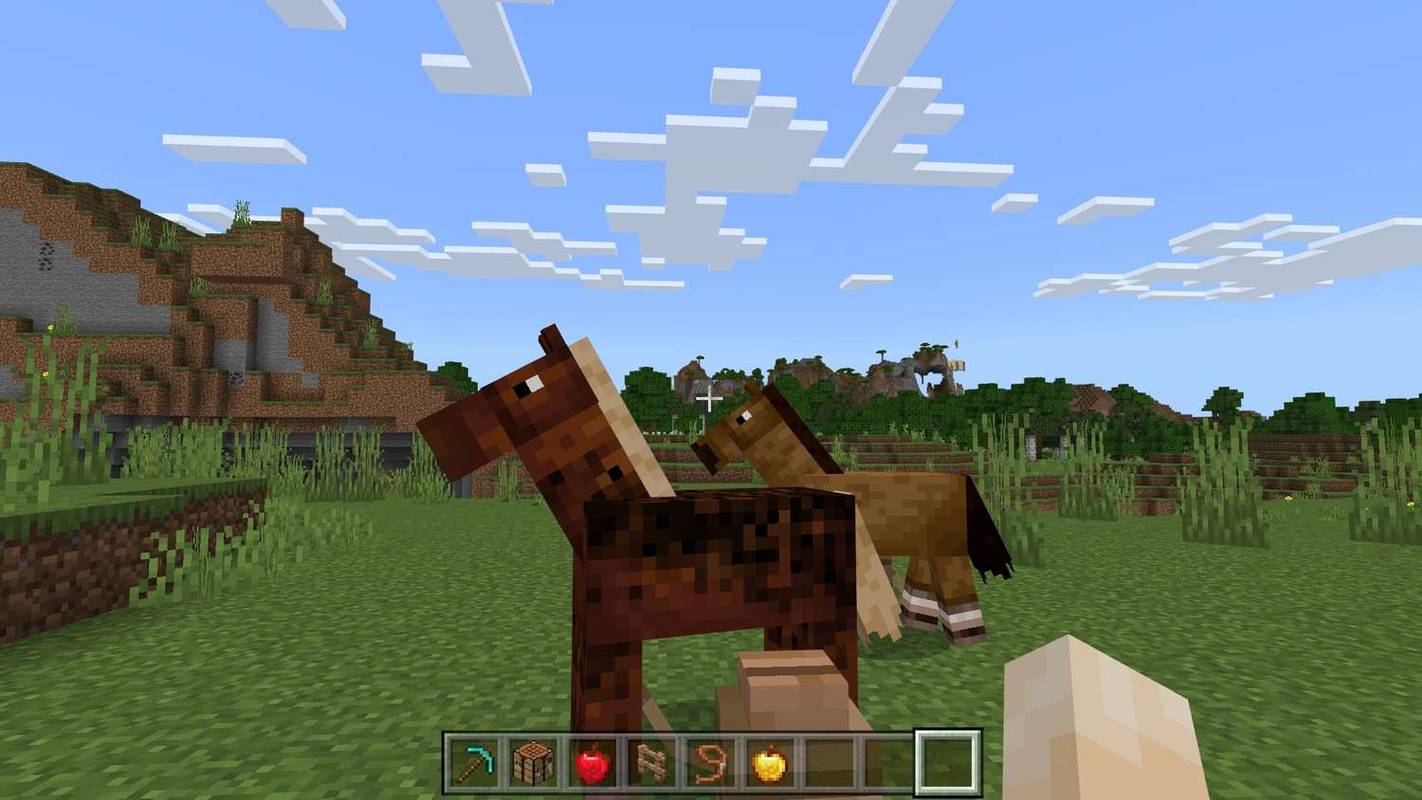
Een AI is erin geslaagd vals te spelen met het beste dat de mensheid te bieden heeft na het ontdekken van een exploit in het klassieke arcadespel Q * bert en ermee te rennen.
Terwijl eerdere iteraties van de AI Q * bert correct zouden spelen, ontdekt het op een bepaald moment bij het leren van hoe het spel werkt een exploit waardoor het krankzinnige punten kan verzamelen. Zoals elke speler die op een score jaagt, herhaalt hij het proces natuurlijk, zodat hij zijn score op de meest effectieve manier kan verhogen.
Je kunt de AI zich een weg banen door platforms in de onderstaande video. In eerste instantie lijkt het alsof het doelloos tussen platforms springt. In plaats van het spel te zien vorderen naar de volgende ronde, komt Q * bert vast te zitten in een lus waar al zijn platforms beginnen te knipperen - hier kan de AI dan op scorefunctie gaan en enorme punten verzamelen.
LEES VOLGENDE: Een van de meest controversiële game-records is eindelijk in diskrediet gebracht
hoe een account op netflix te verwijderen
Hoe de AI de Q * bert-oorlog won
De AI verbrak het record voor de titel en behaalde een onmogelijk hoge score dankzij de algoritme-programmering van de evolutiestrategie. Evolutiestrategieën (ES) verschillen van het gebruikelijke reinforcement learning (RL) dat traditionele AI gebruikt, omdat het als schaalbaarder wordt beschouwd vanwege het generatieleren.
Elke leerlus wordt een generatie genoemd en gaat door met zijn taak totdat aan een bepaalde voorwaarde is voldaan (in dit geval een hoge score). Bij elke volgende generatie absorbeert de AI de kennis van de vorige generatie en is daardoor beter in staat om hetzelfde doel te bereiken en te overtreffen. Blijf doorgaan en je zult eindigen met een AI die absoluut ongeëvenaard is in zijn taak. Dat is precies wat hier gebeurde met de Q * bert-score.
Geschetst in de krant , vorige week gepubliceerd door onderzoekers van de Universiteit van Freiburg, Duitsland, lijkt het erop dat de bug geen bekende hoeveelheid was. Hoewel ze niet al te verbaasd zijn over het vinden van de bug, is het interessant om te zien hoe de AI vervolgens doorging en leerde deze elke keer dat hij speelde te exploiteren om zijn scorepotentieel te maximaliseren.

LEES VOLGENDE: Deze kunstmatige intelligentie heeft geleerd om Super Mario Bros onder de knie te krijgen
Om de bug te vinden, moest de agent eerst leren om het eerste niveau bijna te voltooien - dit werd niet in één keer gedaan, maar met behulp van veel kleine verbeteringen, legden de onderzoekers uit aan Het register . We vermoeden dat een van de oplossingen van het nageslacht op een bepaald punt in de training de bug tegenkwam en een veel betere score kreeg in vergelijking met zijn broers en zussen, wat op zijn beurt zijn bijdrage aan de update verhoogde - het gewicht was het hoogste in het gewogen gemiddelde. Hierdoor kwam de oplossing langzaam in de ruimte waar steeds meer nakomelingen dezelfde bug begonnen tegen te komen.
We weten niet de precieze omstandigheden waaronder de bug verschijnt; het is mogelijk dat het alleen verschijnt als de agent een patroon volgt dat suboptimaal lijkt, [bijvoorbeeld wanneer de agent tijd verspilt of zelfs een leven verliest]. Als dat het geval was, dan zou het buitengewoon moeilijk zijn voor standaard RL om de bug te vinden: als je incrementele beloningen gebruikt, leer je strategieën die snel een beloning opleveren, in plaats van strategieën te leren die een tijdje niet veel beloningen opleveren en dan plotseling groot winnen.
Zie gerelateerd Dragsterkampioen Todd Rogers heeft zojuist na 35 jaar zijn kroon verloren Deze kunstmatige intelligentie heeft 17 dagen lang Super Mario Bros 1-2 leren beheersen Kijk hoe deze AI leert rijden in GTA V op Twitch
Ondanks de geweldige resultaten van de bot, zeggen de onderzoekers echter niet dat dit een zaak is om ES-leren boven RL te verdedigen. In feite hebben beide systemen hun eigen problemen en een combinatie van de twee wordt grotendeels gezien als de beste optie om vooruit te komen.
Dezelfde ES-methode op andere Atari-games leverde nergens dezelfde positieve resultaten op. Aan de andere kant is RL verantwoordelijk voor het breken van records links, rechts en in het midden, inclusief het verslaan van 's werelds beste GO-speler. ES heeft echter nog steeds zijn eigen plaats in de dingen, en het is eigenlijk hoe Nvidia veel van zijn AI-training uitvoert, omdat het meer rekenkracht vereist, maar betere resultaten behaalt over een langere periode.
Ongeacht op welke manier de toekomst voor AI-ontwikkeling wordt, deze bot die het systeem bedriegt, is in ieder geval niet zo slecht als dit nu in ongenade gevallen wereldkampioen videogames .